Getting the Belgian eID to work on Linux systems should be fairly easy, although some people do struggle with it.
For that reason, there is a lot of third-party documentation out there in the form of blog posts, wiki pages, and other kinds of things. Unfortunately, some of this documentation is simply wrong. Written by people who played around with things until it kind of worked, sometimes you get a situation where something that used to work in the past (but wasn't really necessary) now stopped working, but it's still added to a number of locations as though it were the gospel.
And then people follow these instructions and now things don't work anymore.
One of these revolves around OpenSC.
OpenSC is an open source smartcard library that has support for a pretty large number of smartcards, amongst which the Belgian eID. It provides a PKCS#11 module as well as a number of supporting tools.
For those not in the know, PKCS#11 is a standardized C API for offloading cryptographic operations. It is an API that can be used when talking to a hardware cryptographic module, in order to make that module perform some actions, and it is especially popular in the open source world, with support in NSS, amongst others. This library is written and maintained by mozilla, and is a low-level cryptographic library that is used by Firefox (on all platforms it supports) as well as by Google Chrome and other browsers based on that (but only on Linux, and as I understand it, only for linking with smartcards; their BoringSSL library is used for other things).
The official eID software that we ship through eid.belgium.be, also known as "BeID", provides a PKCS#11 module for the Belgian eID, as well as a number of support tools to make interacting with the card easier, such as the "eID viewer", which provides the ability to read data from the card, and validate their signatures. While the very first public version of this eID PKCS#11 module was originally based on OpenSC, it has since been reimplemented as a PKCS#11 module in its own right, with no lineage to OpenSC whatsoever anymore.
About five years ago, the Belgian eID card was renewed. At the time, a new physical appearance was the most obvious difference with the old card, but there were also some technical, on-chip, differences that are not so apparent. The most important one here, although it is not the only one, is the fact that newer eID cards now use a NIST P-384 elliptic curve-based private keys, rather than the RSA-based ones that were used in the past. This change required some changes to any PKCS#11 module that supports the eID; both the BeID one, as well as the OpenSC card-belpic driver that is written in support of the Belgian eID.
Obviously, the required changes were implemented for the BeID module; however, the OpenSC card-belpic driver was not updated. While I did do some preliminary work on the required changes, I was unable to get it to work, and eventually other things took up my time so I never finished the implementation. If someone would like to finish the work that I started, the preliminal patch that I wrote could be a good start -- but like I said, it doesn't yet work. Also, you'll probably be interested in the official documentation of the eID card.
Unfortunately, in the mean time someone added the Applet 1.8 ATR to the card-belpic.c file, without also implementing the required changes to the driver so that the PKCS#11 driver actually supports the eID card. The result of this is that if you have OpenSC installed in NSS for either Firefox or any Chromium-based browser, and it gets picked up before the BeID PKCS#11 module, then NSS will stop looking and pass all crypto operations to the OpenSC PKCS#11 module rather than to the official eID PKCS#11 module, and things will not work at all, causing a lot of confusion.
I have therefore taken the following two steps:
- The official eID packages now conflict with the OpenSC PKCS#11 module. Specifically only the PKCS#11 module, not the rest of OpenSC, so you can theoretically still use its tools. This means that once we release this new version of the eID software, when you do an upgrade and you have OpenSC installed, it will remove the PKCS#11 module and anything that depends on it. This is normal and expected.
- I have filed a pull request against OpenSC that removes the Applet 1.8 ATR from the driver, so that OpenSC will stop claiming that it supports the 1.8 applet.
When the pull request is accepted, we will update the official eID software to make the conflict versioned, so that as soon as it works again you will again be able to install the OpenSC and BeID packages at the same time.
In the mean time, if you have the OpenSC PKCS#11 module installed on your system, and your eID authentication does not work, try removing it.
A while ago, I saw Stefano's portable monitor, and thought it was very useful. Personally, I rent a desk at an office space where I have a 27" Dell monitor; but I do sometimes use my laptop away from that desk, and then I do sometimes miss the external monitor.
So a few weeks before DebConf, I bought me one myself. The one I got is about a mid-range model; there are models that are less than half the price of the one that I bought, and there are models that are more than double its price, too. ASUS has a very wide range of these monitors; the cheapest model that I could find locally is a 720p monitor that only does USB-C and requires power from the connected device, which presumably if I were to connect it to my laptop with no power connected would half its battery life. More expensive models have features such as wifi connectivity and miracast support, builtin batteries, more connection options, and touchscreen fancyness.
While I think some of these features are not worth the money, I do think that a builtin battery has its uses, and that I would want a decent resolution, so I got a FullHD model with builtin battery.
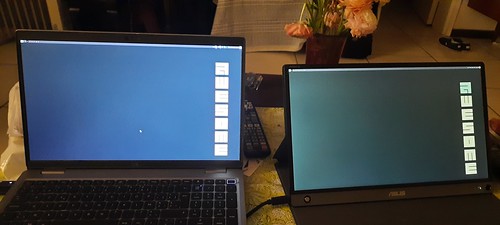
The device comes with a number of useful accessories: a USB-C to USB-C cable for the USB-C connectivity as well as to charge the battery; an HDMI-to-microHDMI cable for HDMI connectivity; a magnetic sleeve that doubles as a back stand; a beefy USB-A charger and USB-A-to-USB-C convertor (yes, I know); and a... pen.
No, really, a pen. You can write with it. Yes, on paper. No, not a stylus. It's really a pen.
Sigh, OK. This one:

OK, believe me now?
Good.
Don't worry, I was as confused about this as you just were when I first found that pen. Why would anyone do that, I thought. So I read the manual. Not something I usually do with new hardware, but here you go.
It turns out that the pen doubles as a kickstand. If you look closely at the picture of the laptop and the monitor above, you may see a little hole at the bottom right of the monitor, just to the right of the power button/LED. The pen fits right there.
Now I don't know what the exact thought process was here, but I imagine it went something like this:
- ASUS wants to make money through selling monitors, but they don't want to spend too much money making them.
- A kickstand is expensive.
- So they choose not to make one, and add a little hole instead where you can put any little stick and make that function as a kickstand.
- They explain in the manual that you can use a pen with the hole as a kickstand. Problem solved, and money saved.
Some paper pusher up the chain decides that if you mention a pen in the manual, you can't not ship a pen
- Or perhaps some lawyer tells them that this is illegal to do in some jurisdictions
- Or perhaps some large customer with a lot of clout is very annoying
So in a meeting, it is decided that the monitor will have a pen going along with it
- So someone in ASUS then goes through the trouble of either designing and manufacturing a whole set of pens that use the same color scheme as the monitor itself, or just sourcing them from somewhere; and those pens are then branded (cheaply) and shipped with the monitors.
It's an interesting concept, especially given the fact that the magnetic sleeve works very well as a stand. But hey.
Anyway, the monitor is very nice; the battery lives longer than the battery of my laptop usually does, so that's good, and it allows me to have a dual-monitor setup when I'm on the road.
And when I'm at the office? Well, now I have a triple-monitor setup. That works well, too.
I've been maintaining a number of Perl software packages recently. There's SReview, my video review and transcoding system of which I split off Media::Convert a while back; and as of about a year ago, I've also added PtLink, an RSS aggregator (with future plans for more than just that).
All these come with extensive test suites which can help me ensure that things continue to work properly when I play with things; and all of these are hosted on salsa.debian.org, Debian's gitlab instance. Since we're there anyway, I configured GitLab CI/CD to run a full test suite of all the software, so that I can't forget, and also so that I know sooner rather than later when things start breaking.
GitLab has extensive support for various test-related reports, and while it took a while to be able to enable all of them, I'm happy to report that today, my perl test suites generate all three possible reports. They are:
- The
coverageregex, which captures the total reported coverage for all modules of the software; it will show the test coverage on the right-hand side of the job page (as in this example), and it will show what the delta in that number is in merge request summaries (as in this example - The JUnit report, which tells GitLab in detail which tests were run, what their result was, and how long the test took (as in this example)
- The cobertura report, which tells GitLab which lines in the software were ran in the test suite; it will show up coverage of affected lines in merge requests, but nothing more. Unfortunately, I can't show an example here, as the information seems to be no longer available once the merge request has been merged.
Additionally, I also store the native perl Devel::Cover report as job artifacts, as they show some information that GitLab does not.
It's important to recognize that not all data is useful. For instance, the JUnit report allows for a test name and for details of the test. However, the module that generates the JUnit report from TAP test suites does not make a distinction here; both the test name and the test details are reported as the same. Additionally, the time a test took is measured as the time between the end of the previous test and the end of the current one; there is no "start" marker in the TAP protocol.
That being said, it's still useful to see all the available information in GitLab. And it's not even all that hard to do:
test:
stage: test
image: perl:latest
coverage: '/^Total.* (\d+.\d+)$/'
before_script:
- cpanm ExtUtils::Depends Devel::Cover TAP::Harness::JUnit Devel::Cover::Report::Cobertura
- cpanm --notest --installdeps .
- perl Makefile.PL
script:
- cover -delete
- HARNESS_PERL_SWITCHES='-MDevel::Cover' prove -v -l -s --harness TAP::Harness::JUnit
- cover
- cover -report cobertura
artifacts:
paths:
- cover_db
reports:
junit: junit_output.xml
coverage_report:
path: cover_db/cobertura.xml
coverage_format: cobertura
Let's expand on that a bit.
The first three lines should be clear for anyone who's used GitLab CI/CD
in the past. We create a job called test; we start it in the test
stage, and we run it in the perl:latest docker image. Nothing
spectacular here.
The coverage line contains a regular expression. This is applied by
GitLab to the output of the job; if it matches, then the first bracket
match is extracted, and whatever that contains is assumed to contain the
code coverage percentage for the code; it will be reported as such in
the GitLab UI for the job that was ran, and graphs may be drawn to show
how the coverage changes over time. Additionally, merge requests will
show the delta in the code coverage, which may help deciding whether to
accept a merge request. This regular expression will match on a line of
that the cover program will generate on standard output.
The before_script section installs various perl modules we'll need
later on. First, we intall
ExtUtils::Depends. My code
uses
ExtUtils::MakeMaker,
which ExtUtils::Depends depends on (no pun intended); obviously, if your
perl code doesn't use that, then you don't need to install it. The next
three modules -- Devel::Cover,
TAP::Harness::JUnit and
Devel::Cover::Report::Cobertura
are necessary for the reports, and you should include them if you want
to copy what I'm doing.
Next, we install declared dependencies, which is probably a good idea
for you as well, and then we run perl Makefile.PL, which will generate
the Makefile. If you don't use ExtUtils::MakeMaker, update that part to
do what your build system uses. That should be fairly straightforward.
You'll notice that we don't actually use the Makefile. This is because
we only want to run the test suite, which in our case (since these are
PurePerl modules) doesn't require us to build the software first. One
might consider that this makes the call of perl Makefile.PL useless,
but I think it's a useful test regardless; if that fails, then obviously
we did something wrong and shouldn't even try to go further.
The actual tests are run inside a script snippet, as is usual for
GitLab. However we do a bit more than you would normally expect; this is
required for the reports that we want to generate. Let's unpack what we
do there:
cover -delete
This deletes any coverage database that might exist (e.g., due to caching or some such). We don't actually expect any coverage database, but it doesn't hurt.
HARNESS_PERL_SWITCHES='-MDevel::Cover'
This tells the TAP harness that we want it to load the Devel::Cover
addon, which can generate code coverage statistics. It stores that in
the cover_db directory, and allows you to generate all kinds of
reports on the code coverage later (but we don't do that here, yet).
prove -v -l -s
Runs the actual test suite, with verbose output, shuffling (aka,
randomizing) the test suite, and adding the lib directory to perl's
include path. This works for us, again, because we don't actually need
to compile anything; if you do, then -b (for blib) may be required.
ExtUtils::MakeMaker creates a test target in its Makefile, and usually
this is how you invoke the test suite. However, it's not the only way to
do so, and indeed if you want to generate a JUnit XML report then you
can't do that. Instead, in that case, you need to use the prove, so
that you can tell it to load the TAP::Harness::JUnit module by way of
the --harness option, which will then generate the JUnit XML report.
By default, the JUnit XML report is generated in a file
junit_output.xml. It's possible to customize the filename for this
report, but GitLab doesn't care and neither do I, so I don't. Uploading
the JUnit XML format tells GitLab which tests were run and
Finally, we invoke the cover script twice to generate two coverage
reports; once we generate the default report (which generates HTML files
with detailed information on all the code that was triggered in your
test suite), and once with the -report cobertura parameter, which
generates the cobertura XML format.
Once we've generated all our reports, we then need to upload them to
GitLab in the right way. The native perl report, which is in the
cover_db directory, is uploaded as a regular job artifact, which we
can then look at through a web browser, and the two XML reports are
uploaded in the correct way for their respective formats.
All in all, I find that doing this makes it easier to understand how my code is tested, and why things go wrong when they do.
The DebConf video team has been sprinting in preparation for DebConf 23 which will happen in Kochi, India, in September of this year.

Present were Nicolas "olasd" Dandrimont, Stefano "tumbleweed" Rivera, and yours truly. Additionally, Louis-Philippe "pollo" Véronneau and Carl "CarlFK" Karsten joined the sprint remotely from across the pond.
Thank you to the DPL for agreeing to fund flights, food, and accomodation for the team members. We would also like to extend a special thanks to the Association April for hosting our sprint at their offices.
We made a lot of progress:
- Now that Debian Bookworm has been released, we updated our ansible repository to work with Debian Bookworm. This encountered some issues, but nothing earth-shattering, and almost all of them are handled. The one thing that is still outstanding is that jibri requires OpenJDK 11, which is no longer in bookworm; a solution for that will need to be found in the longer term, but as jibri is only needed for online conferences, it is not quite as urgent (Stefano, Louis-Philippe).
- In past years, we used open "opsis" hardware to do screen grabbing. While these work, upstream development has stalled, and their intended functionality is also somewhat more limited than we would like. As such, we experimented with a USB-based HDMI capture device, and after playing with it for some time, decided that it is a good option and that we would like to switch to it. Support for the specific capture device that we played with has now also been added to all the relevant places. (Stefano, Carl)
- Another open tool that we have been using is voctomix, a software video mixer. Its upstream development has also stalled somewhat . While we managed to make it work correctly on Bookworm, we decided that to ensure long-term viability for the team, it would be preferable if we had an alternative. As such, we quickly investigated Nageru, Sesse's software video mixer, and decided that it can everything we need (and, probably, more). As such, we worked on implementing a user interface theme that would work with our specific requirements. Work on this is still ongoing, and we may decide that we are not ready yet for the switch by the time DebConf23 comes along, but we do believe that the switch is at least feasible. While working on the theme, we found a bug which Sesse quickly fixed for us after a short amount of remote debugging, so, thanks for that! (Stefano, Nicolas, Sesse)
- Our current streaming architecture uses HLS, which requires MPEG-4-based codecs. While fully functional, MPEG-4 is not the most modern of codecs anymore, not to mention the fact that it is somewhat patent-encumbered (even though some of these patents are expired by now). As such, we investigated switching to the AV1 codec for live streaming. Our ansible repository has been updated to support live streaming using that codec; the post-event transcoding part will follow soon enough. Special thanks, again, to Sesse, for pointing out a few months ago on Planet Debian that this is, in fact, possible to do. (Wouter)
- Apart from these big-ticket items, we also worked on various small maintenance things: upgrading, fixing, and reinstalling hosts and services, filing budget requests, and requesting role emails. (all of the team, really).
It is now Sunday the 23rd at 14:15, and while the sprint is coming to an end, we haven't quite finished yet, so some more progress can still be made. Let's see what happens by tonight.
All in all, though, we believe that the progress we made will make the DebConf Videoteam's work a bit easier in some areas, and will make things work better in the future.
See you in Kochi!
Since before I got involved in the eID back in 2014, we have provided official packages of the eID for Red Hat Enterprise Linux. Since RHEL itself requires a license, we did this, first, by using buildbot and mock on a Fedora VM to set up a CentOS chroot in which to build the RPM package. Later this was migrated to using GitLab CI and to using docker rather than VMs, in an effort to save some resources. Even later still, when Red Hat made CentOS no longer be a downstream of RHEL, we migrated from building in a CentOS chroot to building in a Rocky chroot, so that we could continue providing RHEL-compatible packages. Now, as it seems that Red Hat is determined to make that impossible too, I investigated switching to actually building inside a RHEL chroot rather than a derivative one. Let's just say that might be a challenge...
[root@b09b7eb7821d ~]# mock --dnf --isolation=simple --verbose -r rhel-9-x86_64 --rebuild eid-mw-5.1.11-0.v5.1.11.fc38.src.rpm --resultdir /root --define "revision v5.1.11"
ERROR: /etc/pki/entitlement is not a directory is subscription-manager installed?
Okay, so let's fix that.
[root@b09b7eb7821d ~]# dnf install -y subscription-manager
(...)
Complete!
[root@b09b7eb7821d ~]# mock --dnf --isolation=simple --verbose -r rhel-9-x86_64 --rebuild eid-mw-5.1.11-0.v5.1.11.fc38.src.rpm --resultdir /root --define "revision v5.1.11"
ERROR: No key found in /etc/pki/entitlement directory. It means this machine is not subscribed. Please use
1. subscription-manager register
2. subscription-manager list --all --available (available pool IDs)
3. subscription-manager attach --pool <POOL_ID>
If you don't have Red Hat subscription yet, consider getting subscription:
https://access.redhat.com/solutions/253273
You can have a free developer subscription:
https://developers.redhat.com/faq/
Okay... let's fix that too, then.
[root@b09b7eb7821d ~]# subscription-manager register
subscription-manager is disabled when running inside a container. Please refer to your host system for subscription management.
Wut.
[root@b09b7eb7821d ~]# exit
wouter@pc220518:~$ apt-cache search subscription-manager
wouter@pc220518:~$
As I thought, yes.
Having to reinstall the docker host machine with Fedora just so I can build Red Hat chroots seems like a somewhat excessive requirement, which I don't think we'll be doing that any time soon.
We'll see what the future brings, I guess.
As I blogged before, I've been working on a Planet Venus replacement. This is necessary, because Planet Venus, unfortunately, has not been maintained for a long time, and is a Python 2 (only) application which has never been updated to Python 3.
Python not being my language of choice, and my having plans to do far more than just the "render RSS streams" functionality that Planet Venus does, meant that I preferred to write "something else" (in Perl) rather than updating Planet Venus to modern Python.
Planet Grep has been running PtLink for over a year now, and my plan had been to update the code so that Planet Debian could run it too, but that has been taking a bit longer.
This month, I have finally been able to work on this, however. This screenshot shows two versions of Planet Debian:
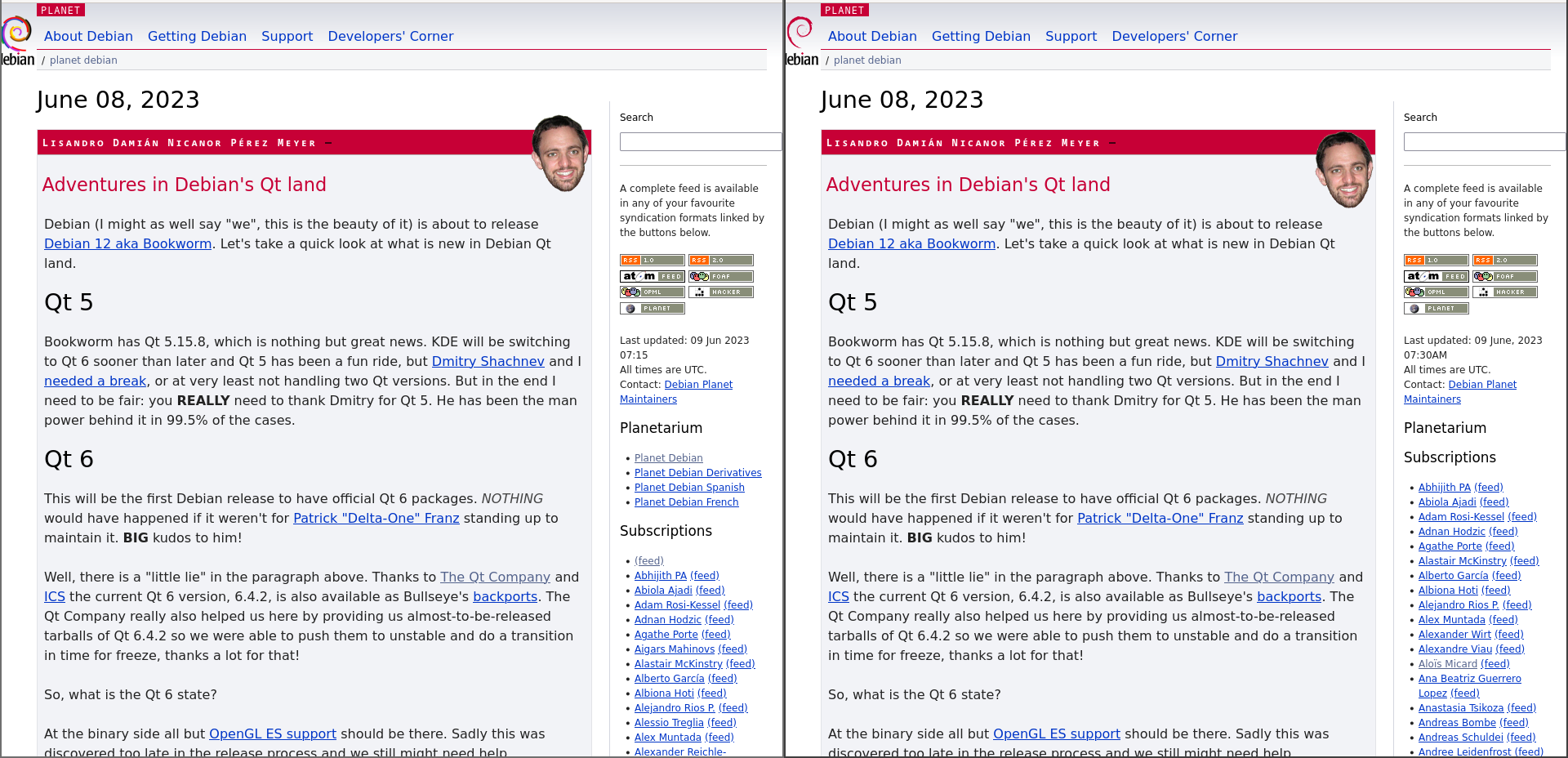
The rendering on the left is by Planet Venus, the one on the right is by PtLink.
It's not quite ready yet, but getting there.
Stay tuned.
The Debian Videoteam has been sprinting in Cape Town, South Africa -- mostly because with Stefano here for a few months, four of us (Jonathan, Kyle, Stefano, and myself) actually are in the country on a regular basis. In addition to that, two more members of the team (Nicolas and Louis-Philippe) are joining the sprint remotely (from Paris and Montreal).

(Kyle and Stefano working on things, with me behind the camera and Jonathan busy elsewhere.)
We've made loads of progress! Some highlights:
- We did a lot of triaging of outstanding bugs and merge requests against our ansible repository. Stale issues were closed, merge requests have been merged (or closed when they weren't relevant anymore), and new issues that we found while working on them were fixed. We also improved our test coverage for some of our ansible roles, and modernized as well as improved the way our documentation is built. (Louis-Philippe, Stefano, Kyle, Wouter, Nicolas)
- Some work was done on SReview, our video review and transcode tool: I fixed up the metadata export code and did some other backend work, while Stefano worked a bit on the frontend, bringing it up to date to use bootstrap 4, and adding client-side filtering using vue. Future work on this will allow editing various things from the webinterface -- currently that requires issuing SQL commands directly. (Wouter and Stefano)
- Jonathan explored new features in OBS. We've been using OBS for our "loopy" setup since DebConf20, which is used for the slightly more interactive sponsor loop that is shown in between talks. The result is that we'll be able to simplify and improve that setup in future (mini)DebConf instances. (Jonathan)
- Kyle had a look at options for capturing hardware. We currently use Opsis boards, but they are not an ideal solution, and we are exploring alternatives. (Kyle)
- Some package uploads happened! libmedia-convert-perl will now (hopefully) migrate to testing; and if all goes well, a new version of SReview will be available in unstable soon.
The sprint isn't over yet (we're continuing until Sunday), but loads of things have already happened. Stay tuned!
A notorious ex-DD decided to post garbage on his site in which he links my name to the suicide of Frans Pop, and mentions that my GPG key is currently disabled in the Debian keyring, along with some manufactured screenshots of the Debian NM site that allegedly show I'm no longer a DD. I'm not going to link to the post -- he deserves to be ridiculed, not given attention.
Just to set the record straight, however:
Frans Pop was my friend. I never treated him with anything but respect. I do not know why he chose to take his own life, but I grieved for him for a long time. It saddens me that Mr. Notorious believes it a good idea to drag Frans' name through the mud like this, but then, one can hardly expect anything else from him by this point.
Although his post is mostly garbage, there is one bit of information that is correct, and that is that my GPG key is currently no longer in the Debian keyring. Nothing sinister is going on here, however; the simple fact of the matter is that I misplaced my OpenPGP key card, which means there is a (very very slight) chance that a malicious actor (like, perhaps, Mr. Notorious) would get access to my GPG key and abuse that to upload packages to Debian. Obviously we can't have that -- certainly not from him -- so for that reason, I asked the Debian keyring maintainers to please disable my key in the Debian keyring.
I've ordered new cards; as soon as they arrive I'll generate a new key and perform the necessary steps to get my new key into the Debian keyring again. Given that shipping key cards to South Africa takes a while, this has taken longer than I would have initially hoped, but I'm hoping at this point that by about halfway September this hurdle will have been taken, meaning, I will be able to exercise my rights as a Debian Developer again.
As for Mr. Notorious, one can only hope he will get the psychiatric help he very obviously needs, sooner rather than later, because right now he appears to be more like a goat yelling in the desert.
Ah well.
Sometimes, it's useful to get a notification that a command has finished doing something you were waiting for:
make my-large-program && notify-send "compile finished" "success" || notify-send "compile finished" "failure"
This will send a notification message with the title "compile finished", and a body of "success" or "failure" depending on whether the command completed successfully, and allows you to minimize (or otherwise hide) the terminal window while you do something else, which can be a very useful thing to do.
It works great when you're running something on your own machine, but what if you're running it remotely?
There might be something easy to do, but I whipped up a bit of Perl instead:
#!/usr/bin/perl -w
use strict;
use warnings;
use Glib::Object::Introspection;
Glib::Object::Introspection->setup(
basename => "Notify",
version => "0.7",
package => "Gtk3::Notify",
);
use Mojolicious::Lite -signatures;
Gtk3::Notify->init();
get '/notify' => sub ($c) {
my $msg = $c->param("message");
if(!defined($msg)) {
$msg = "message";
}
my $title = $c->param("title");
if(!defined($title)) {
$title = "title";
}
app->log->debug("Sending notification '$msg' with title '$title'");
my $n = Gtk3::Notify::Notification->new($title, $msg, "");
$n->show;
$c->render(text => "OK");
};
app->start;
This requires the packages libglib-object-introspection-perl,
gir1.2-notify-0.7, and libmojolicious-perl to be installed, and can
then be started like so:
./remote-notify daemon -l http://0.0.0.0:3000/
(assuming you did what I did and saved the above as "remote-notify")
Once you've done that, you can just curl a notification message to yourself:
curl 'http://localhost:3000/notify?title=test&message=test+body'
Doing this via localhost is rather silly (much better to use notify-send for that), but it becomes much more interesting if you're going to run this to your laptop from a remote system.
An obvious TODO would be to add in some form of security, but that's left as an exercise to the reader...
I run Debian on my laptop (obviously); but occasionally, for $DAYJOB, I have some work to do on Windows. In order to do so, I have had a Windows 10 VM in my libvirt configuration that I can use.
A while ago, Microsoft issued Windows 11. I recently found out that all the components for running Windows 11 inside a libvirt VM are available, and so I set out to upgrade my VM from Windows 10 to Windows 11. This wasn't as easy as I thought, so here's a bit of a writeup of all the things I ran against, and how I fixed them.
Windows 11 has a number of hardware requirements that aren't necessary for Windows 10. There are a number of them, but the most important three are:
- Secure Boot is required (Windows 10 would still boot on a machine without Secure Boot, although buying hardware without at least support for that hasn't been possible for several years now)
- A v2.0 TPM module (Windows 10 didn't need any TPM)
- A modern enough processor.
So let's see about all three.
A modern enough processor
If your processor isn't modern enough to run Windows 11, then you can probably forget about it (unless you want to use qemu JIT compilation -- I dunno, probably not going to work, and also not worth it if it were). If it is, all you need is the "host-passthrough" setting in libvirt, which I've been using for a long time now. Since my laptop is less than two months old, that's not a problem for me.
A TPM 2.0 module
My Windows 10 VM did not have a TPM configured, because it wasn't needed. Luckily, a quick web search told me that enabling that is not hard. All you need to do is:
- Install the
swtpmandswtpm-toolspackages Adding the TPM module, by adding the following XML snippet to your VM configuration:
<devices> <tpm model='tpm-tis'> <backend type='emulator' version='2.0'/> </tpm> </devices>Alternatively, if you prefer the graphical interface, click on the "Add hardware" button in the VM properties, choose the TPM, set it to Emulated, model TIS, and set its version to 2.0.
You're done!
Well, with this part, anyway. Read on.
Secure boot
Here is where it gets interesting.
My Windows 10 VM was old enough that it was configured for the older
i440fx chipset. This one is limited to PCI and IDE, unlike the more
modern q35 chipset (which supports PCIe and SATA, and does not support
IDE nor SATA in IDE mode).
There is a UEFI/Secure Boot-capable BIOS for qemu, but it apparently
requires the q35 chipset,
Fun fact (which I found out the hard way): Windows stores where its boot partition is somewhere. If you change the hard drive controller from an IDE one to a SATA one, you will get a BSOD at startup. In order to fix that, you need a recovery drive. To create the virtual USB disk, go to the VM properties, click "Add hardware", choose "Storage", choose the USB bus, and then under "Advanced options", select the "Removable" option, so it shows up as a USB stick in the VM. Note: this takes a while to do (took about an hour on my system), and your virtual USB drive needs to be 16G or larger (I used the libvirt default of 20G).
There is no possibility, using the buttons in the virt-manager GUI, to
convert the machine from i440fx to q35. However, that doesn't mean
it's not possible to do so. I found that the easiest way is to use the
direct XML editing capabilities in the virt-manager interface; if you
edit the XML in an editor it will produce error messages if something
doesn't look right and tell you to go and fix it, whereas the
virt-manager GUI will actually fix things itself in some cases (and
will produce helpful error messages if not).
What I did was:
- Take backups of everything. No, really. If you fuck up, you'll have to start from scratch. I'm not responsible if you do.
- Go to the Edit->Preferences option in the VM manager, then on the "General" tab, choose "Enable XML editing"
- Open the Windows VM properties, and in the "Overview" section, go to the "XML" tab.
- Change the value of the
machineattribute of thedomain.os.typeelement, so that it sayspc-q35-7.0. - Search for the
domain.devices.controllerelement that haspciin itstypeattribute andpci-rootin itsmodelone, and set themodelattribute topcie-rootinstead. - Find all
domain.devices.disk.targetelements, setting theirdev=hdXtodev=sdX, andbus="ide"tobus="sata" - Find the USB controller (
domain.devices.controllerwithtype="usb", and set itsmodeltoqemu-xhci. You may also want to addports="15"if you didn't have that yet. Perhaps also add a few PCIe root ports:
<controller type="pci" index="1" model="pcie-root-port"/> <controller type="pci" index="2" model="pcie-root-port"/> <controller type="pci" index="3" model="pcie-root-port"/>
I figured out most of this by starting the process for creating a new VM, on the last page of the wizard that pops up selecting the "Modify configuration before installation" option, going to the "XML" tab on the "Overview" section of the new window that shows up, and then comparing that against what my current VM had.
Also, it took me a while to get this right, so I might have forgotten
something. If virt-manager gives you an error when you hit the Apply
button, compare notes against the VM that you're in the process of
creating, and copy/paste things from there to the old VM to make the
errors go away. As long as you don't remove configuration that is
critical for things to start, this shouldn't break matters permanently
(but hey, use your backups if you do break -- you have backups, right?)
OK, cool, so now we have a Windows VM that is... unable to boot. Remember what I said about Windows storing where the controller is? Yeah, there you go. Boot from the virtual USB disk that you created above, and select the "Fix the boot" option in the menu. That will fix it.
Ha ha, only kidding. Of course it doesn't.
I honestly can't tell you everything that I fiddled with, but I think the bit that eventually fixed it was where I chose "safe mode", which caused the system to do a hickup, a regular reboot, and then suddenly everything was working again. Meh.
Don't throw the virtual USB disk away yet, you'll still need it.
Anyway, once you have it booting again, you will now have a machine that theoretically supports Secure Boot, but you're still running off an MBR partition. I found a procedure on how to convert things from MBR to GPT that was written almost 10 years ago, but surprisingly it still works, except for the bit where the procedure suggests you use diskmgmt.msc (for one thing, that was renamed; and for another, it can't touch the partition table of the system disk either).
The last step in that procedure says to restart your computer!,
which is fine, except at this point you obviously need to switch over to
the TianoCore firmware, otherwise you're trying to read a UEFI boot
configuration on a system that only supports MBR booting, which
obviously won't work. In order to do that, you need to add a loader
element to the domain.os element of your libvirt configuration:
<loader readonly="yes" type="pflash">/usr/share/OVMF/OVMF_CODE_4M.ms.fd</loader>
When you do this, you'll note that virt-manager automatically adds an
nvram element. That's fine, let it.
I figured this out by looking at the documentation for enabling Secure Boot in a VM on the Debian wiki, and using the same trick as for how to switch chipsets that I explained above.
Okay, yay, so now secure boot is enabled, and we can install Windows 11! All good? Well, almost.
I found that once I enabled secure boot, my display reverted to a 1024x768 screen. This turned out to be because I was using older unsigned drivers, and since we're using Secure Boot, that's no longer allowed, which means Windows reverts to the default VGA driver, and that only supports the 1024x768 resolution. Yeah, I know. The solution is to download the virtio-win ISO from one of the links in the virtio-win github project, connecting it to the VM, going to Device manager, selecting the display controller, clicking on the "Update driver" button, telling the system that you have the driver on your computer, browsing to the CD-ROM drive, clicking the "include subdirectories" option, and then tell Windows to do its thing. While there, it might be good to do the same thing for unrecognized devices in the device manager, if any.
So, all I have to do next is to get used to the completely different user interface of Windows 11. Sigh.
Oh, and to rename the "w10" VM to "w11", or some such. Maybe.